Gabriele Tassi, Simone Martin Marotta (Expert.ai)
TL;DR: The Concept Extraction and Categorisation Engine transform unstructured documents into structured, ontology-compliant data. By combining LLM agents with traditional tools, it ensures explainability, traceability, and adaptability across domains.
Keywords: Information extraction, Knowledge base, Ontology-driven AI, LLM agents, Document processing, Explainability, CyclOps.
Finding reliable information in long reports or technical documents can often feel overwhelming. Whether in research, industry, or administration, professionals need more than just text search. They require structured, contextualised knowledge that aligns directly with their domain’s ontology. As part of the EU-funded CyclOps project, our team has developed the Concept Extraction and Categorization Engine. This service automatically turns unstructured documents into structured, ontology-aligned data, making information easier to analyse, reuse, and validate.
Unlike traditional information extraction tools, which often rely on rigid rules or predefined templates, our engine combines the flexibility of Large Language Model (LLM) agents with the rigor of ontology-based schemas. This hybrid approach ensures that extracted information is not only semantically accurate but also formally consistent with the ontology defined in the Integrated Knowledge Base (IKB).
Our service is designed with real-world interoperability in mind. It supports algorithms sourced from both open-source initiatives and internal libraries and extends functionality to include non-machine learning tasks like search strategies and model optimisation. Current development efforts are focused on testing and validating the AI Marketplace in various domains, including tourism, the Green Deal, public procurement, and manufacturing.
Providing a bridge between raw data and the right models for a given application, CeADAR’s recommendation service helps data scientists and business owners focus on insights, not just infrastructure or code. CyclOps makes algorithm selection faster, smarter, and more useful, tailored to every dataset and user need.
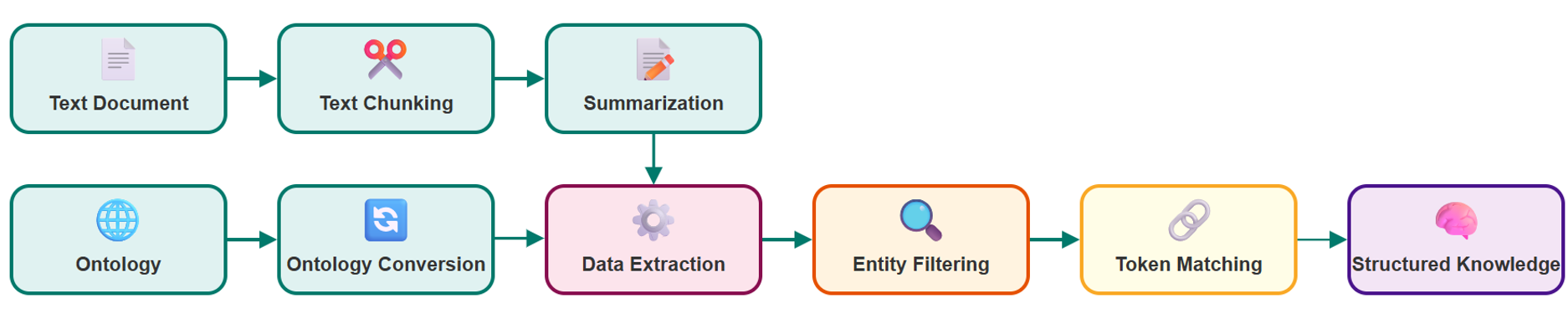
From Text to Knowledge: How It Works
The engine processes documents through a structured pipeline designed for scalability and transparency:
- Text Chunking: Large documents are split into manageable sections.
- Ontology Conversion: ontologies in TTL format are converted into Pydantic models, which act as a schema for extraction.
- Summarisation: text chunks are summarised to reduce redundancy and highlight key points.
- Structured Data Extraction: information is extracted from summaries, aligning with the ontology models.
- Entity Filtering: non-relevant or absent entities, that may occur due to hallucinations, are removed.
- Token Matching: extracted values are linked back to their original text occurrences, ensuring full explainability.
The result is a JSON output that contains not only structured information but also direct references to the text passages from which the data was derived.
A practical example
To make the approach more concrete, the images below illustrates a practical example showing both the input text and the corresponding structured JSON output produced by the component. This example demonstrates how the engine extracts ontology-aligned entities and relations from raw text while preserving full traceability back to the original document.
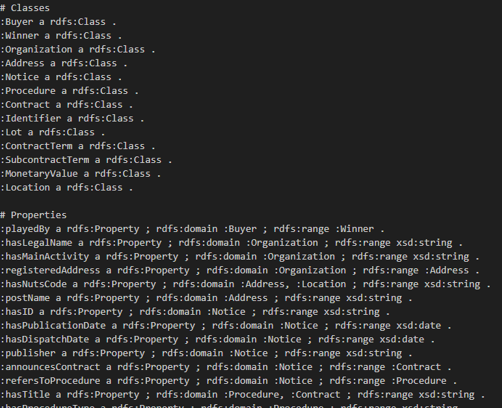

Figure 1 Input ontology
Figure 2 Input text
Output
Procedure
Procedure Entry 1
- Procedure Name: Gestión y explotación del servicio de bar-restaurante
- Tokens:
- start: 159, end: 212, found_by: regex
- Tokens:
- Hasdescription: el contrato que en base al presente pliego se realiza, tiene por objeto la contratación de la gestión y explotación del servicio de bar-restaurante en el local sito en el Centro Sociocultural de la lo…
- Tokens:
- start: 66, end: 268, found_by: regex
- Tokens:
- Hasproceduretype: Servicios
- Tokens:
- start: 7785, end: 7794, found_by: regex
- start: 17916, end: 17924, found_by: regex
- start: 23311, end: 23320, found_by: regex
- start: 23879, end: 23888, found_by: regex
- Tokens:
Lot
Lot Entry 1
- Lot Name: Gestión y explotación del servicio de bar-restaurante
- Tokens:
- start: 160, end: 212, found_by: regex
- Tokens:
…
Since the component is still in active development, examples like this are particularly useful to show how the system is evolving. In this case, the extracted metadata is tied to specific ontology classes and relations defined in the reference dataspace (in this case, procurements). These structured outputs enable advanced querying capabilities, such as logical filters (e.g., date ≥ 2005) and semantic similarity searches, which significantly improve findability and reuse of domain-specific information in instances of unstructured knowledge.
Why it matters
The Concept Extraction and Categorisation Engine addresses three major challenges in information extraction:
- Scalability: efficient processing of large documents thanks to chunking, caching, and modular pipeline design.
- Ontology Compatibility: dynamic generation of Pydantic models from ontologies ensures broad adaptability.
- Explainability: Token-level references ensure that users can always trace extracted information back to its source.
This makes the tool highly versatile, capable of serving multiple domains such as healthcare, public administration, manufacturing, or environmental monitoring, wherever ontology-based knowledge representation is key.
Looking ahead
Current work focuses on improving scalability for larger ontologies and documents, as well as refining the explanation mechanism so that extracted information is not only semantically correct but also formally consistent with the original text. Planned enhancements include parallel processing and advanced evidence-tracking methods.
By bridging unstructured documents and structured ontologies, the Concept Extraction and Categorisation Engine enables researchers, analysts, and decision-makers focus on insights rather than information overload, thereby turning complexity into clarity.