We live in a world where data is king, and our computers get more powerful daily. But are we using them to their full potential?
Traditional ways of organising code and running applications are great, but they are starting to feel like old-school methods when compared to what modern technology can offer. As always, we can do much better than just splitting data and tasks! Think about it: today’s systems pack processing power, but our algorithms often struggle to leverage that potential fully.
We need to rethink how we build and run applications to unlock the awesome capabilities of modern computing.
For instance, let’s look at how traditional division of resources may use them to run different applications or workflows:
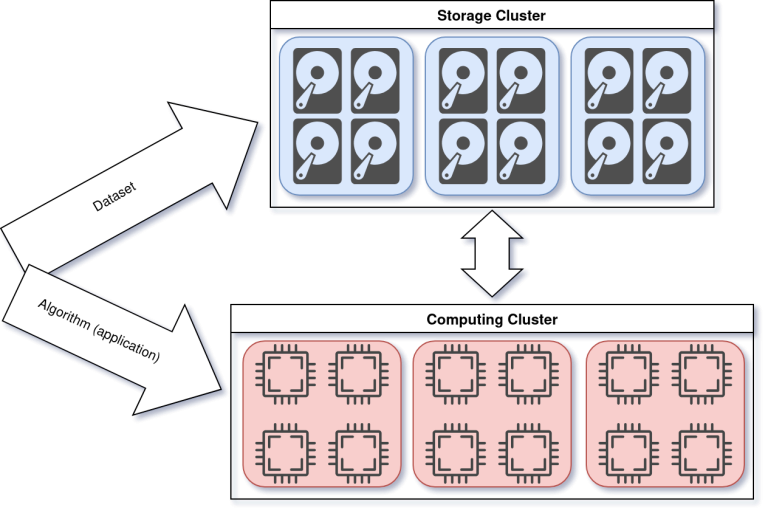
Diagram, where the Storage Cluster (on the top) has nodes with storage resources and the Computing Cluster (on the bottom) has nodes with computational resources.
The dataset goes to the Storage Cluster, while the algorithm (the application/workflow) goes to the computing cluster. There is communication between both clusters.
As we can see, all the application data would be persisted in a storage cluster (or a storage system). In this storage cluster, we would have the structures the application requires in their persistent representation (e.g., binary objects, database, etc.).
To run any workload, we would run that application in the computing cluster, where most computation resources are. During the execution, the application would retrieve data from the storage cluster. Some frameworks can help manage the lifecycle of all the data, and we can see the relevance of Data Management for complex workflows. Still, even while cost-effective, a storage cluster results in additional latencies and bandwidth bottlenecks. We may be being dramatic, but this configuration is dragging us down.
We propose bringing the computing and storage resources closer and letting data reside next to the computation resources that will be used. This is shown in the following Diagram:

Diagram with a single cluster with its nodes having storage and computing resources. This cluster receives both the application and its data.
When data is moved closer to computation, performance increases, and resource utilization improves. This idea is not new, but the proposed architecture allows for achieving this goal with a simple programming model and a very low entry barrier for domain experts by leveraging the integration of dataClay and COMPSs. These tools belong to the BSC software catalogue and are available as open-source projects at https://compss.bsc.es and https://dataclay.bsc.es. They have been extensively used in various use cases exploiting efficiently distributed and HPC environments. They have demonstrated to be a perfect combination for running CyclOps workloads.
The future landscape
As data continues to grow exponentially, the importance of these technologies will only increase.
By embracing parallel processing, workflow automation, advanced data management practices, and collaborative data spaces, organizations can unlock new insights, accelerate innovation, and gain a competitive edge in the ever-evolving digital world.